Spencer Bryson
MSc Computer Science graduate from Ontario Tech University. Previously a research assistant for the Data Science Lab and student fellow at IBM Centre for Advanced Studies.
Interests includes: ML/AI Techniques Databases Data Science Big Data Information Visualization Distributed Computing
Research
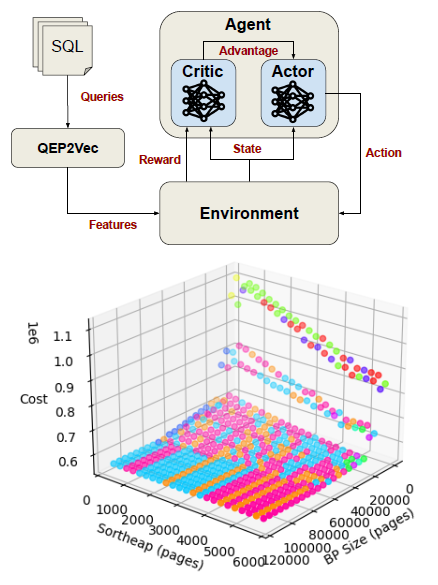
Automatic Knobs-Tuning for DB2 using Deep Reinforcement Learning
Ontario Tech University Master's Thesis 2021
Modern database management systems have hundreds of different configuration parameters (knobs) that control various aspects of how they behave and perform. These knobs must be properly tuned in order to maximize the performance of the database for a given query workload. Traditionally, database administrators would be responsible for database performance tuning. However, manual configuration tuning is a difficult process for humans, as there are hundreds of different inter-dependent knobs to be tuned. Different queries and workloads also benefit from configurations differently, there is no one single database configuration that can fit all scenarios. We propose BLUTune, a system to automatically produce effective knob configuration for IBM DB2. BLUTune utilizes deep reinforcement learning and features a unique transfer-learning approach to training which allows for fast learning. In experimental validation, BLUTune demonstrates its capability of producing effective configurations across differing sizes of the TPC-DS OLAP benchmark in a timely manner.
Spencer Bryson, Ontario Tech University
View thesis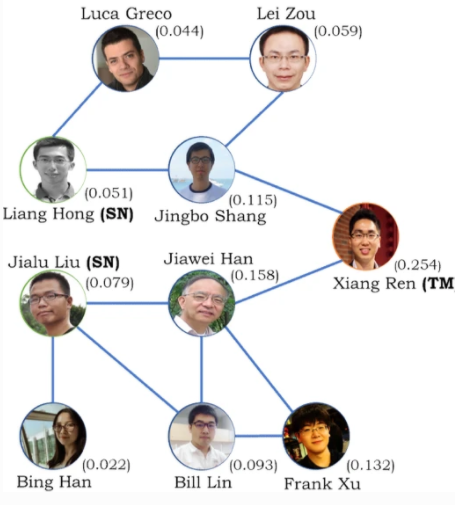
Robust keyword search in large attributed graphs
Published in Information Retrieval Journal 2020
There is a growing need to explore attributed graphs such as social networks, expert networks, and biological networks. A well-known mechanism for non-technical users to explore such graphs is keyword search, which receives a set of query keywords and returns a connected subgraph that contains the keywords. However, existing approaches, such as methods based on shortest paths between nodes containing the query keywords, may generate weakly-connected answers as they ignore the structure of the whole graph. To address this issue, we formulate and solve the robust keyword search problem for attributed graphs to find strongly-connected answers. We prove that the problem is NP-hard and we propose a solution based on a random walk with restart (RWR). To improve the efficiency and scalability of RWR, we use Monte Carlo approximation and we also propose a distributed version, which we implement in Apache Spark. Finally, we provide experimental evidence of the efficiency and effectiveness of our approach on real-world graphs.
Spencer Bryson, Heidar Davoudi, Lukasz Golab, Mehdi Kargar, Yuliya Lytvyn, Piotr Mierzejewski, Jaroslaw Szlichta, Morteza Zihayat: Robust keyword search in large attributed graphs. Inf. Retr. J. 23(5): 502-524 (2020)
View publication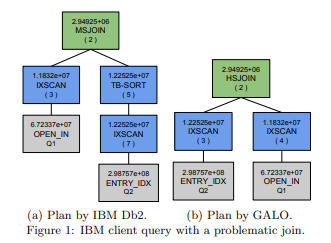
GALO: Guided Automated Learning for re-Optimization.
Published in VLDB 2019
Query performance problem determination is usually performed manually in consultation with experts through the analysis of query plans. However, this is an excessively time consuming, human error-prone, and costly process. GALO is a novel system that automates this process. The tool automatically learns recurring problem patterns in query plans over workloads in an offline learning phase to build a knowledge base of plan rewrite remedies. GALO's knowledge base is built on RDF and SPARQL, which is well-suited for manipulating and querying over SQL query plans, which are graphs themselves. It then uses the knowledge base online to re-optimize queries queued for execution to improve performance, often quite dramatically.
Guilherme Damasio, Spencer Bryson, Vincent Corvinelli, Parke Godfrey, Piotr Mierzejewski, Jaroslaw Szlichta, Calisto Zuzarte: GALO: Guided Automated Learning for re-Optimization. Proc. VLDB Endow. 12(12): 1778-1781 (2019)
View publication